
On 30 November 2022, OpenAI released its latest chat bot technology: ChatGPT. With its natural and human-like responses, the AI community has been questioning whether this new technology had passed the Turing Test.
Are we truly there? What happens behind the scenes, and will it disrupt delay analysis or the forensic world in general? In this 2-part introductory article, we will dive into the main techniques ChatGPT is based on. Then, as both a construction delay expert and CTO at Orizo Consult, I will provide insights into the potential use cases and future of the forensic industry.
One thing is for sure: if Microsoft is willing to invest 10 billion USD into OpenAI, ChatGPT is no small beast.
ChatGPT is powered by GPT-3
ChatGPT is part of the GPT-3 family of Natural Language Processing (NLP) models. In order to understand ChatGPT, we will need to look at the foundations of GPT-3: a story of sentence statistics, semantical vectors, and word predictions.
Generative Pre-trained Transformer
The GPT acronym stands for Generative Pre-trained Transformer. It means the model creates new text, has been trained on non-specialized contents (it knows how to read), and relies upon the Transformer technology. A Transformer is an algorithm which is able to convert sentences into semantic meaning (their linguistic meaning) and then convert it back into a different sentence. The output text will depend on the task we wish to accomplish. A non-exhaustive list is presented below:
- Rephrasing – Similar semantic meaning, similar length, different words.
- Shortening – Similar semantic meaning, shorter length.
- Extending – Similar semantic meaning, longer length.
- Translating – Similar semantic meaning, different dictionary of words.
- Extrapolating – Additional semantic meaning.
Infer semantic meaning from statistics
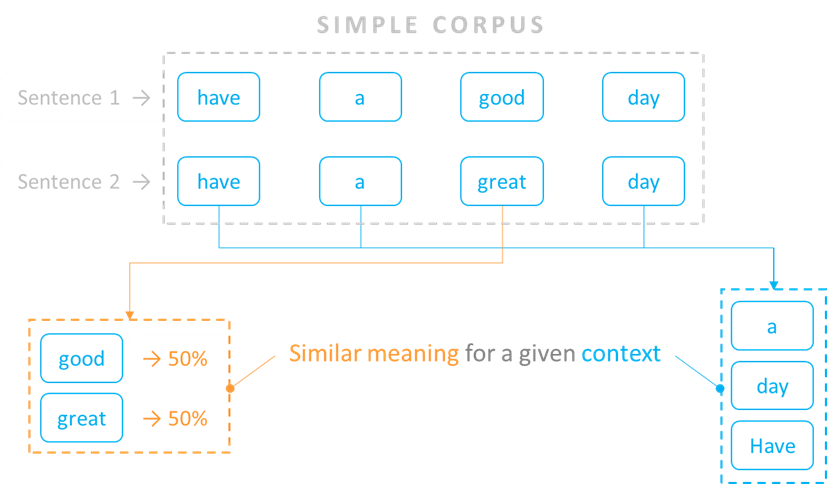
During its training, GPT-3 read millions of documents (a corpus) such as Wikipedia, books, news articles, product reviews, etc. From these readings, the model measured the frequency at which a word appeared close to other words in a sentence. That is, it measured the probability for a word to appear under a specific context of other words.
Let’s consider a simple example where our corpus only includes two sentences: “have a good day”, and “have a great day”. The model would measure that ‘good’ and ‘great’ are equally used under the same context of words, i.e., at a 50% ratio.
The general idea behind this statistical analysis is that if two words are commonly used under similar contexts, their semantic meaning must be similar too. The model identifies the contexts under which words can be interchangeable to some degree, which then defines the strength of their semantic meaning in that context.
Embeddings explained
Embedding is the method through which the model stores semantic information in memory. We will see how the semantic meaning of a word can be quantified according to context, and how this can be extrapolated to capture the meaning of entire sentences or paragraphs.
Embedding words into vectors
Based on the statistical analysis mentioned in the previous section, the model is able to infer axes – also called dimensions – where the strength of a word for a given semantic meaning can be calculated.
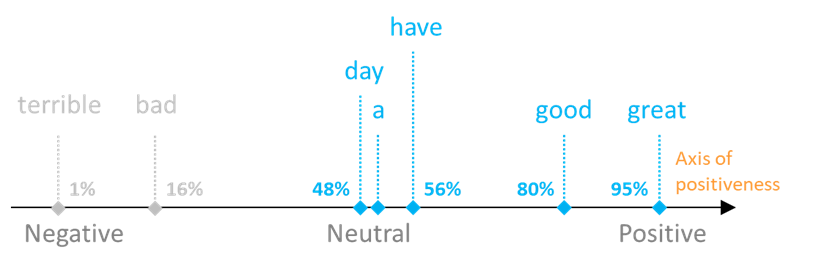
Continuing with our example, we could imagine that ‘good’ and ‘great’ would both be captured to be strong in the ‘positiveness’ axis, where ‘great’ would probably be slightly stronger than ‘good’, and the other three words (‘have’, ‘a’ and ‘day’) would have a neutral ‘positiveness’. Finally, if the words ‘bad’ or ‘terrible’ were also present in our corpus, we could expect that they would be characterized by weak and very weak ‘positiveness’. This strength is calculated as a percentage, which can then be stored in memory. A graphical representation of these values is shown below:
The more axes a model can dispose of, the better it gets at capturing the diversity of the meanings of a word. Thus, we may locate the words of our corpus against a second axis, which for example could reflect the size of things: ‘largeness’.
The two-axis description of these words can be visualized on the two-dimension chart below, where a few extra words have also been added, for the sake of further illustrating the principle.
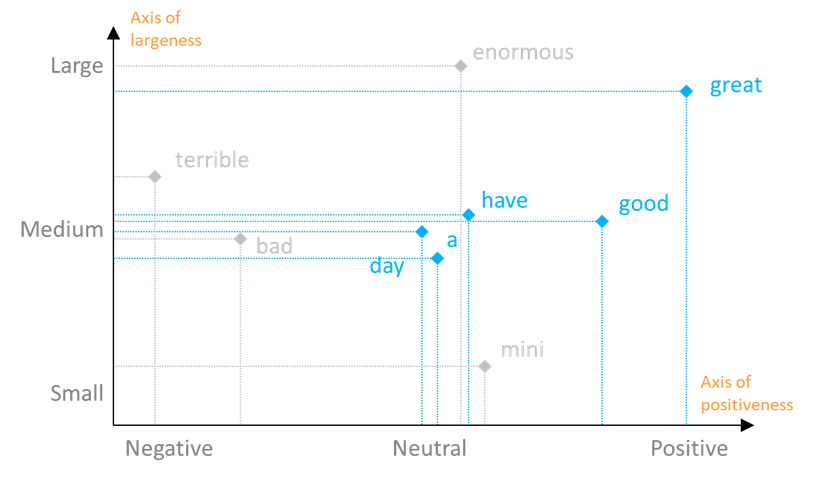
We note that ‘good’ is neutral on the ‘largeness’ axis, whilst ‘great’ is strong on both the ‘positiveness’ and ‘largeness’ axes. Depending on the context of a sentence, the model will interpret the meaning of ‘great’ as either positive or large.
The semantic meaning of each word is stored in a 1-column table, where each row corresponds to the strength of the word in a given semantical dimension. These tables are called embeddings. Mathematically speaking, they are nothing more than multi-dimensional vectors.
In our example, we would store each word inside a 2-dimensional embedding. In reality though, the embeddings generated by GPT-3 include thousands of dimensions, each representing an axis of ‘characteristic-ness’.
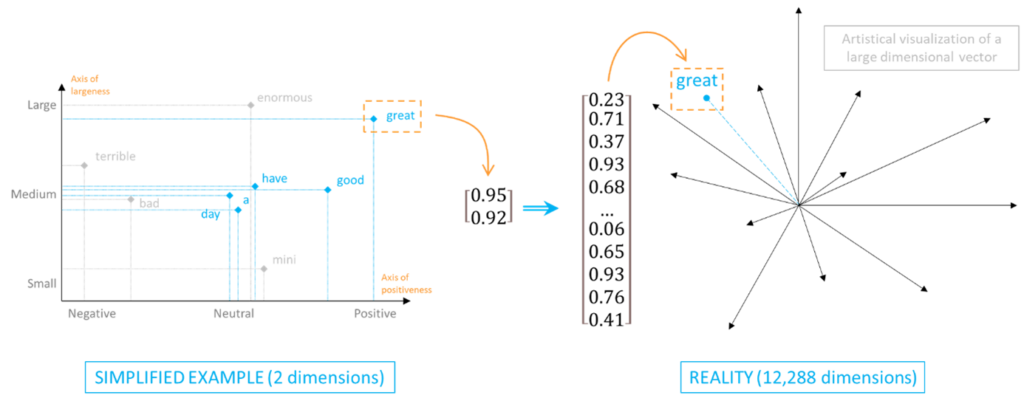
As you may have already guessed, it becomes challenging for a human being to visualize that many dimensions. In practice, a semantical axis rarely reflects the strength of a word along a unique meaning. It rather reflects a trend resulting from the combination of multiple notions. As humans, we are mostly unable to decipher the full semantical notions behind each dimension. As a machine, GPT-3 is unable to understand the sense of the semantical notion it identified: it merely detected that specific words were used in a similar fashion under specific contexts.
Adding or subtracting embeddings
The magic of word embeddings starts with algebra. Since semantic meanings can be stored within vectors, which are nothing more than tables of numbers, why not try some maths? For example, how about summing the embedding of ‘kid’ with that of ‘old’, and hoping to get something like ‘adult’ as a result?
Back in 2013, Google researchers Tomas Mikolov et al. published their famous paper introducing word2vec, a word embedding algorithm from which many subsequent embedding techniques were derived. At page 2, the paper says:

The word2vec algorithm paved the road toward the era of semantical algebra. It was now possible to infer words from other words, based on their linguistical meaning.
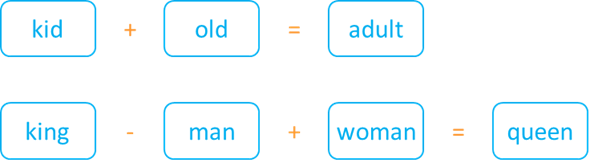
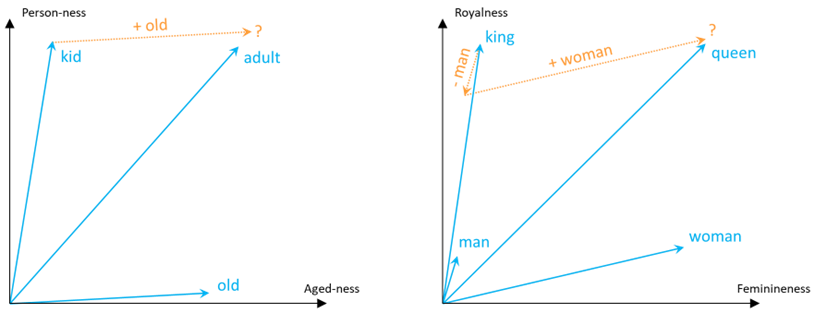
Behind the scenes, what the model identified was that the difference between not ‘old’ and ‘old’ was similar to the difference between ‘adult’ and ‘kid’. Likewise, it identified that the main difference between ‘man’ and ‘woman’ was similar to the main difference between ‘king’ and ‘queen’. Considering a 2D representation along the relevant semantical dimensions, the additions and subtractions would show as follows:
Paragraph embeddings
Just like adding embeddings allows one to infer new words, calculating the average of a sub-set of embeddings allows one to derive the overall meaning of a group of words. For example, one may derive the meaning of a sentence by averaging the embeddings of all the words the sentence is made of. One of the novelties of the Transformer technology used by GPT-3 is that it considers the position of the words in the sentence, hence capturing additional semantic information when compared to grossly calculating an average.
Once able to calculate the embedding of a sentence, the same principle can be applied in order to calculate the embeddings of paragraphs.
GPT-3 leverages embeddings to re-formulate text
We have seen that one of the fundamental techniques behind GPT-3 is the embedding of words, sentences, or paragraphs. In the second part of this article, we will see how the model is able to translate embeddings back into sentences that are structurally and semantically correct.
Before heading there, we can however already get a first feel of what GPT-3 and by extension ChatGPT may be good at:
- Re-writing a paragraph with a similar meaning but different words.
- Generating summaries: re-write with fewer words.
- Converting a paragraph into keywords.
- Performing rich searches by meaning as opposed to keywords.
A few use-case examples are explored below.
Paraphrasing
Probably one of the most direct techniques used with ChatGPT, paraphrasing allows one to re-write a paragraph whilst maintaining its overall meaning. It is also possible to train the model to amplify certain aspects of the rewording.
In the example below, we ask ChatGPT to rewrite into British English, whilst at the same time aiming for a specific audience and requesting to improve readability.

Summarising
Another technique often leveraged is GPT-3’s ability to rewrite a paragraph or set of paragraphs with fewer words, whilst preventing the loss of the most relevant meaning.
This is a powerful feature that can enable senior staff to review documents they may otherwise never get the time to open and would typically delegate to junior members. One should nonetheless not negate the risk that GPT miscalculate the relevance of some information in the original text, which would then be omitted in the summary. There is always a risk in delegating. Is it riskier to rely on AI instead of junior staff? I guess the answer to this question will evolve dramatically in the years to come.
One should always be cautious not to delegate the screening of potentially critical documents. For the rest, the right balance resides in the odd equilibrium between time, money, and the magnitude of the assessment. AI would probably allow screening documents no one would have ever considered before.
In an era where experts and lawyers are handed over hundreds of gigabits of documents, whilst at the same time pressured for a cost-effective delivery, AI-assisted screening is an advantage. I also suspect it will enable the claiming of damages which up to now were often too costly for being properly substantiated. Would you consider preparing a fully-fledged disruption claim?
Keywords extraction
This technique, which consists in summarizing a paragraph into just a few words, is based on the model’s ability to identify the relevance or centrality of each word to the overall paragraph: the salience. The most salient words can then be combined in order to calculate one or several keywords which best reflect their meaning.
The technique can be used with emails, reports, claims, or any other business documents to generate labels. These documents may then be grouped or searched by label. It is also possible to train the model to return the most relevant keyword amongst a given list, or to provide their relevance. Whilst it is not the most ergonomic user interface for performing the task, ChatGPT is able to do it:

During document screening, one may wish to identify which sections of which documents are the most relevant to specific matters. These sections could then be grouped accordingly.
In the future, we could also envisage a similar system where electronic Discovery would be governed by such keyword relevance queries.
Semantic searches
Since the inception of web search engines, we have been used to search by keyword. This technique is characterized by two main flaws: (i) a single keyword may contain multiple meanings, which adds noise to the search result, and (ii) an entry containing synonyms of the searched keyword may not show in the results.
There have been improvements with search engines, which are notably now able to deal with synonyms, but we are still far from being able to search a precise idea. What is more, it is also hard to add context in order to refine a search. ChatGPT allows to express an idea and search for it in the corpus.

Coming soon…
In the second part of this article, we will see how sentence completion works, which is the principle that allows ChatGPT to convert embeddings back into human-like responses. We will explore the two techniques commonly used to train natural language AI to respond accurately, and will see how this could offer opportunities for the forensic industry.
