
Este artículo forma parte de la serie Cutting Edge Delay Analysis , que también está disponible como un newsletter de LinkedIn.
El 30 de noviembre de 2022, OpenAI lanzó su última tecnología de chat bot: ChatGPT. Con sus respuestas naturales y parecidas a las humanas, la comunidad de IA se ha cuestionado si esta nueva tecnología había superado la Prueba de Turing.
¿Estamos realmente ahí? ¿Qué ocurre entre bastidores?, ¿alterará el análisis de retrasos o el mundo forense en general?. En este artículo introductorio de 2 partes, nos sumergiremos en las principales técnicas en las que se basa ChatGPT. A continuación, como experto en retrasos en la construcción y CTO de Orizo Consult, ofreceré información sobre los posibles casos de uso y el futuro del sector forense.
Una cosa es segura: si Microsoft está dispuesto a invertir 10.000 millones de dólares en OpenAI, ChatGPT no es una bestia pequeña.
ChatGPT funciona con GPT-3
ChatGPT forma parte de la familia GPT-3 de modelos de Procesamiento del Lenguaje Natural (PLN). Para entender ChatGPT, tendremos que examinar los fundamentos de GPT-3: una historia de estadísticas de frases, vectores semánticos y predicciones de palabras.
Transformador generativo pre-entrenado
El acrónimo GPT significa Generative Pre-trained Transformer (transformador generativo pre-entrenado). Significa que el modelo crea texto nuevo, ha sido entrenado con contenidos no especializados (sabe leer) y se basa en la tecnología Transformer. Un Transformer es un algoritmo capaz de convertir frases en significado semántico (su significado lingüístico) y luego volver a convertirlo en una frase diferente. El texto de salida dependerá de la tarea que queramos realizar. A continuación se presenta una lista no exhaustiva:
- Reformulación – Significado semántico similar, longitud similar, palabras diferentes.
- Acortamiento – Significado semántico similar, menor longitud.
- Extender – Significado semántico similar, mayor longitud.
- Traducir – Significado semántico similar, diccionario de palabras diferente.
- Extrapolar – Significado semántico adicional.
Inferir el significado semántico a partir de estadísticas
Durante su entrenamiento, GPT-3 leyó millones de documentos (un corpus) como Wikipedia, libros, artículos de noticias, reseñas de productos, etc. A partir de estas lecturas, el modelo midió la frecuencia con la que una palabra aparecía cerca de otras en una frase. Es decir, midió la probabilidad de que una palabra apareciera en un contexto específico de otras palabras.
Consideremos un ejemplo sencillo en el que nuestro corpus sólo incluye dos frases: «que tenga un buen día» y «que tenga un gran día». El modelo mediría que «bueno» y «estupendo» se utilizan por igual en el mismo contexto de palabras, es decir, en una proporción del 50%.
La idea general que subyace a este análisis estadístico es que si dos palabras se utilizan habitualmente en contextos similares, su significado semántico también debe ser similar. El modelo identifica los contextos en los que las palabras pueden ser intercambiables hasta cierto punto, lo que define la fuerza de su significado semántico en ese contexto.
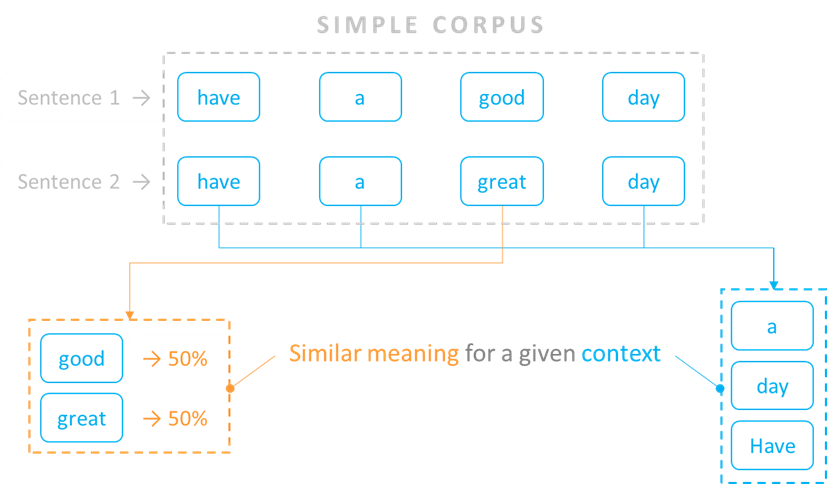
Explicación de las incrustaciones
La incrustación (también conocido como «embedding» en inglés) es el método mediante el cual el modelo almacena la información semántica en la memoria. Veremos cómo puede cuantificarse el significado semántico de una palabra en función del contexto y cómo puede extrapolarse para captar el significado de frases o párrafos enteros.
Incrustación de palabras en vectores
Basándose en el análisis estadístico mencionado en la sección anterior, el modelo es capaz de inferir ejes -también llamados dimensiones– en los que se puede calcular la fuerza de una palabra para un significado semántico determinado.
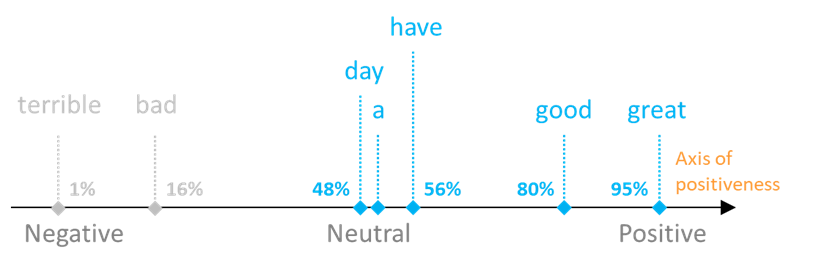
Siguiendo con nuestro ejemplo, podríamos imaginar que tanto «bueno» como «estupendo» se captarían como fuertes en el eje de «positividad», donde «estupendo» probablemente sería ligeramente más fuerte que «bueno», y las otras tres palabras («tener», «a» y «día») tendrían una «positividad» neutra. Por último, si las palabras «malo» o «terrible» también estuvieran presentes en nuestro corpus, podríamos esperar que se caracterizaran por una «positividad» débil y muy débil. Esta fuerza se calcula en forma de porcentaje, que puede almacenarse en la memoria. A continuación se muestra una representación gráfica de estos valores:
Cuantos más ejes pueda disponer un modelo, mejor captará la diversidad de significados de una palabra. Así, podemos situar las palabras de nuestro corpus en un segundo eje, que por ejemplo podría reflejar el tamaño de las cosas: «grandeza «.
La descripción en dos ejes de estas palabras puede visualizarse en el gráfico de dos dimensiones que figura a continuación, en el que también se han añadido algunas palabras más, con el fin de ilustrar mejor el principio.
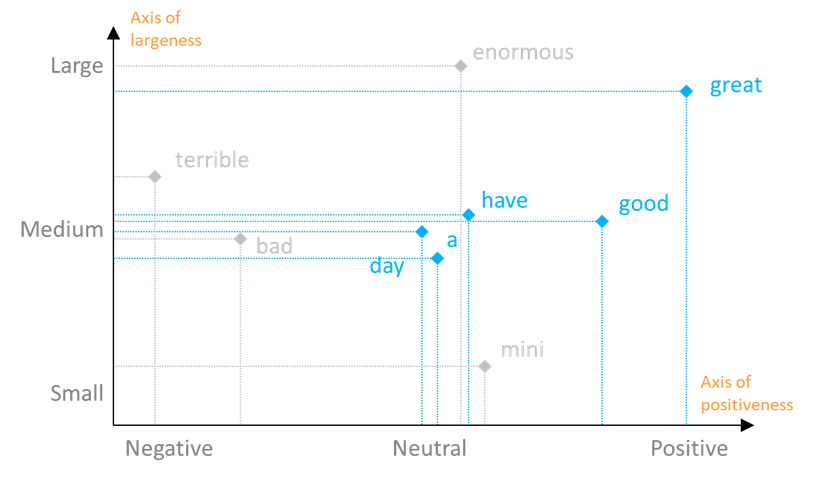
Observamos que «bueno» es neutro en el eje «grandeza», mientras que «grande» es fuerte tanto en el eje «positividad» como en el eje «grandeza». Dependiendo del contexto de la frase, el modelo interpretará el significado de «grande» como positivo o grande.
El significado semántico de cada palabra se almacena en una tabla de 1 columna, donde cada fila corresponde a la fuerza de la palabra en una dimensión semántica determinada. Estas tablas se denominan incrustaciones. Desde el punto de vista matemático, no son más que vectores multidimensionales.
En nuestro ejemplo, almacenaríamos cada palabra dentro de una incrustación bidimensional. En realidad, las incrustaciones generadas por GPT-3 incluyen miles de dimensiones, cada una de las cuales representa un eje de «caracteristi-quesa».
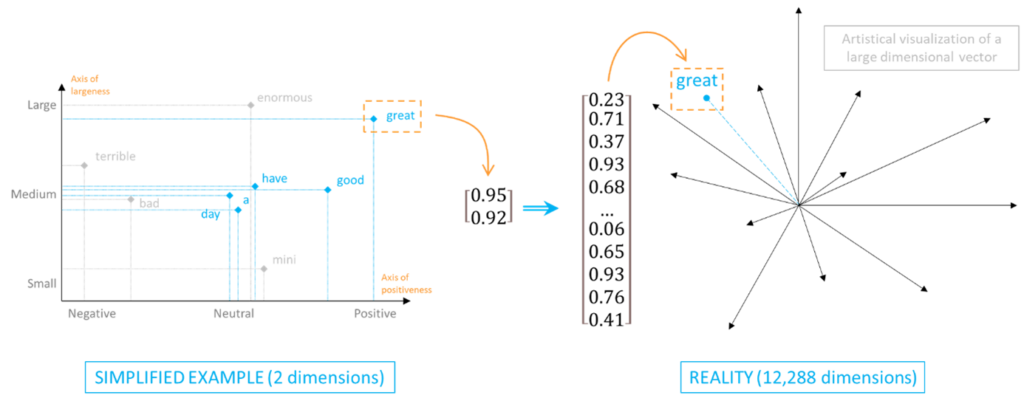
Como ya habrá adivinado, para un ser humano resulta complicado visualizar tantas dimensiones. En la práctica, un eje semántico rara vez refleja la fuerza de una palabra a lo largo de un significado único. Más bien refleja una tendencia resultante de la combinación de múltiples nociones. Como humanos, la mayoría de las veces somos incapaces de descifrar todas las nociones semánticas que hay detrás de cada dimensión. Como máquina, GPT-3 es incapaz de comprender el sentido de la noción semántica que identifica: se limita a detectar que determinadas palabras se utilizan de forma similar en contextos específicos.
Sumar o restar incrustaciones
La magia de las incrustaciones de palabras empieza con el álgebra. Puesto que los significados semánticos pueden almacenarse en vectores, que no son más que tablas de números, ¿por qué no probar con las matemáticas? Por ejemplo, ¿qué tal si sumamos la incrustación de «niño» con la de «viejo» y esperamos obtener como resultado algo parecido a «adulto»?
Ya en 2013, los investigadores de Google Tomas Mikolov et al. publicaron su famoso artículo en el que presentaban word2vec, un algoritmo de incrustación de palabras del que se derivaron muchas técnicas de incrustación posteriores. En la página 2, el documento dice:

El algoritmo word2vec allanó el camino hacia la era del álgebra semántica. Ahora era posible inferir palabras a partir de otras palabras, basándose en su significado lingüístico.
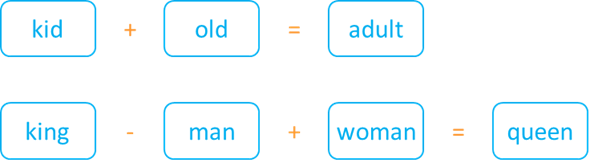
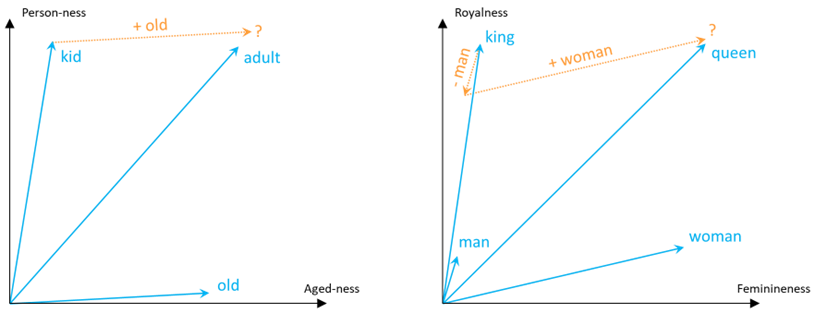
Entre bastidores, lo que el modelo identificó fue que la diferencia entre no «viejo» y «viejo» era similar a la diferencia entre «adulto» y «niño». Asimismo, identificó que la diferencia principal entre «hombre» y «mujer» era similar a la diferencia principal entre «rey» y «reina». Considerando una representación 2D a lo largo de las dimensiones semánticas pertinentes, las adiciones y sustracciones se mostrarían de la siguiente manera:
Incrustación de párrafos
Al igual que la suma de incrustaciones permite deducir nuevas palabras, el cálculo de la media de un subconjunto de incrustaciones permite deducir el significado global de un grupo de palabras. Por ejemplo, se puede deducir el significado de una frase calculando la media de las incrustaciones de todas las palabras que la componen. Una de las novedades de la tecnología Transformer utilizada por GPT-3 es que tiene en cuenta la posición de las palabras en la frase, por lo que capta información semántica adicional en comparación con el cálculo bruto de una media.
Una vez que se puede calcular la incrustación de una frase, se puede aplicar el mismo principio para calcular las incrustaciones de los párrafos.
GPT-3 aprovecha las incrustaciones para reformular el texto
Hemos visto que una de las técnicas fundamentales de GPT-3 es la incrustación de palabras, frases o párrafos. En la segunda parte de este artículo veremos cómo el modelo es capaz de traducir las incrustaciones en frases estructural y semánticamente correctas.
Sin embargo, antes de llegar a ese punto, ya podemos hacernos una primera idea de para qué puede servir GPT-3 y, por extensión, ChatGPT:
- Reescribir un párrafo con un significado similar pero con palabras diferentes.
- Generar resúmenes: reescribir con menos palabras.
- Convertir un párrafo en palabras clave.
- Realizar búsquedas enriquecidas por significado en lugar de por palabras clave.
A continuación se analizan algunos ejemplos de uso.
Parafraseando
Probablemente una de las técnicas más directas utilizadas con ChatGPT, el parafraseo permite reescribir un párrafo manteniendo su sentido global. También es posible entrenar el modelo para que amplifique ciertos aspectos de la reformulación.
En el ejemplo siguiente, pedimos a ChatGPT que reescriba en inglés británico, al tiempo que se dirige a un público específico y solicita mejorar la legibilidad.

Resumiendo
Otra técnica que se aprovecha a menudo es la capacidad de GPT-3 para reescribir un párrafo o un conjunto de párrafos con menos palabras, evitando al mismo tiempo la pérdida del significado más relevante.
Se trata de una potente función que puede permitir a los altos cargos revisar documentos que, de otro modo, nunca tendrían tiempo de abrir y que normalmente delegarían en miembros subalternos. No obstante, no hay que descartar el riesgo de que el GPT calcule mal la relevancia de alguna información del texto original, que luego se omitiría en el resumen. Delegar siempre conlleva un riesgo. ¿Es más arriesgado confiar en la IA que en el personal subalterno? Supongo que la respuesta a esta pregunta evolucionará drásticamente en los próximos años.
Siempre hay que tener cuidado de no delegar la filtración de los documentos potencialmente críticos. Por lo demás, el equilibrio adecuado reside en el extraño equilibrio entre tiempo, dinero y magnitud de la evaluación. La IA probablemente permitiría seleccionar documentos que nadie habría considerado antes.
En una época en la que los peritos y abogados reciben cientos de gigabits de documentos, al tiempo que se les presiona para que la entrega sea rentable, el control asistido por IA es una ventaja. También sospecho que permitirá reclamar daños y perjuicios que hasta ahora solían ser demasiado costosos para estar debidamente justificados. ¿Consideraría la posibilidad de preparar una reclamación por interrupción del servicio en toda regla?
Palabras clave extracción
Esta técnica, que consiste en resumir un párrafo en unas pocas palabras, se basa en la capacidad del modelo para identificar la relevancia o centralidad de cada palabra en el conjunto del párrafo: la Prominencia. A continuación, las palabras más salientes pueden combinarse para calcular una o varias palabras clave que reflejen mejor su significado.
Esta técnica puede utilizarse con correos electrónicos, informes, reclamaciones o cualquier otro documento comercial para generar etiquetas. A continuación, estos documentos pueden agruparse o buscarse por etiqueta. También es posible entrenar el modelo para que devuelva la palabra clave más relevante entre una lista dada, o para que proporcione su relevancia. Aunque no es la interfaz de usuario más ergonómica para realizar la tarea, ChatGPT es capaz de hacerlo:

Durante la selección de los documentos, puede que se desee identificar qué secciones de qué documentos son las más relevantes para asuntos concretos. Estas secciones podrían agruparse en consecuencia.
En el futuro, también podríamos prever un sistema similar en el que el descubrimiento electrónico se rigiera por estas consultas de relevancia de palabras clave.
Búsquedas semánticas
Desde los inicios de los buscadores web, estamos acostumbrados a buscar por palabra clave. Esta técnica se caracteriza por dos defectos principales: (i) una sola palabra clave puede contener múltiples significados, lo que añade ruido al resultado de la búsqueda, y (ii) una entrada que contenga sinónimos de la palabra clave buscada puede no aparecer en los resultados.
Se han producido mejoras en los motores de búsqueda, que ahora son capaces de tratar sinónimos, pero aún estamos lejos de poder buscar una idea precisa. Además, es difícil añadir contexto para afinar la búsqueda. ChatGPT permite expresar una idea y buscarla en el corpus.

Próximamente…
En la segunda parte de este artículo, veremos cómo funciona la finalización de frases, que es el principio que permite a ChatGPT convertir las incrustaciones en respuestas similares a las humanas. Exploraremos las dos técnicas utilizadas habitualmente para entrenar a la IA en lenguaje natural para que responda con precisión, y veremos cómo esto podría ofrecer oportunidades para la industria forense.
